# In-Depth: Deploy with TGI
In this tutorial, we will deploy a text generation interface ([TGI](https://huggingface.co/docs/text-generation-inference/index)) endpoint hosting `deepseek-ai/deepseek-llm-7b-chat` large language model. [TGI](https://huggingface.co/docs/text-generation-inference/index) is one of the leading libraries for LLM-serving and inference, supporting [many architectures](https://huggingface.co/docs/text-generation-inference/supported_models) and models that use them.
You can find more information about the model itself from the [Hugging Face model hub](https://huggingface.co/deepseek-ai/deepseek-llm-7b-chat).
## Prerequisites
For this example you need a Python environment running on your local machine, a Hugging Face account to create a Hugging Face token that is used to fetch the model weights and Verda cloud account to create a deployment.
## Model Weights
[TGI](https://huggingface.co/docs/text-generation-inference/index) deployment fetches the model weights from Hugging Face.
In this tutorial we are loading `deepseek-ai/deepseek-llm-7b-chat` model.
{% hint style="success" %}
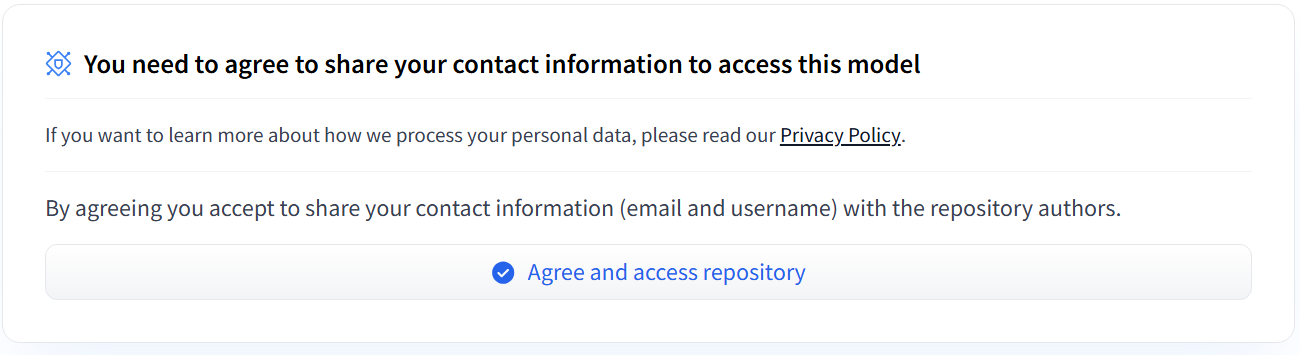
Some models on Hugging Face require the user to accept their usage policy, so please verify this for any model you are deploying. If you have not Agreed to the policy previously, you will see a similar dialog on the model page on Hugging Face:
{% endhint %}
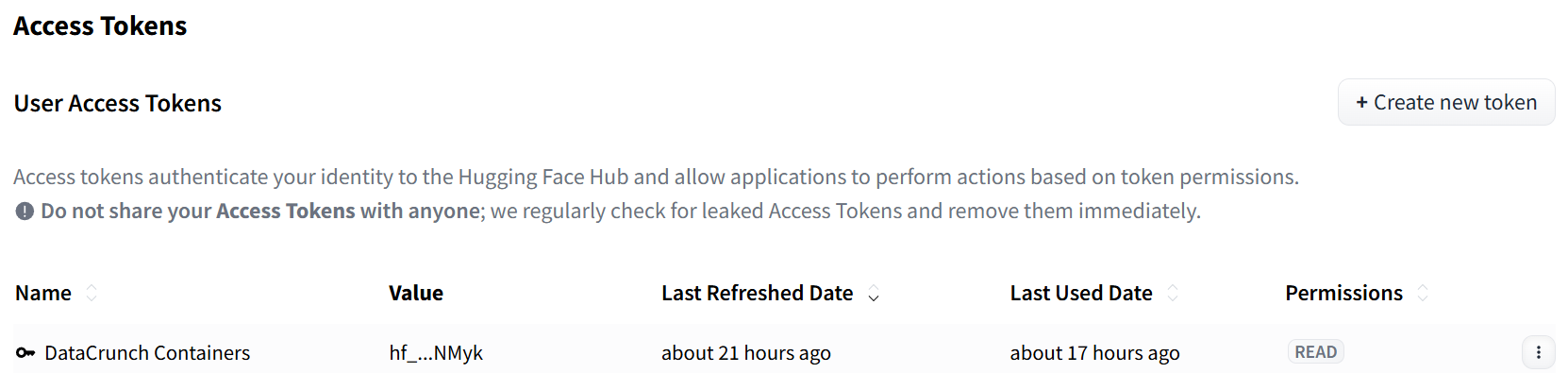
You will also require the `User Access Token` in order to fetch the weights. You can obtain the Access Token in your [Hugging Face account](https://huggingface.co/) by clicking the Profile icon (top right corner) and selecting **Access Tokens**.
For deploying the [TGI](https://huggingface.co/docs/text-generation-inference/index) endpoint, the `READ` permissions are sufficient.
Hugging Face Access Tokens panel
{% hint style="success" %}
Please store the obtained token safely. You will need it for the next steps!
{% endhint %}
## Create the deployment
In this example, we will deploy `deepseek-ai/deepseek-llm-7b-chat` on a General Compute (24 GB VRAM) GPU type. For larger models, you may need to choose one of the other GPU types we offer.
1. Log in to the [Verda cloud console](https://console.verda.com/signin)
2. Create a new project or use existing one, open the project
3. On the left you'll see a navigation menu. Go to **Containers -> New deployment.** Name your deployment and select the Compute Type.
4. We will be using the official [TGI Docker image](https://github.com/huggingface/text-generation-inference/pkgs/container/text-generation-inference), set **Container Image** to `ghcr.io/huggingface/text-generation-inference:3.0.2` You can select another version from the list if you prefer, or leave the version out of the url given and select the one that you wish to use. For this example we use `3.0.2`.
5. Toggle on the **Public** location for your image. You can use the **Private** if you have a private registry, paired with credentials. For this example we use the public registry.
6. Make sure your preferred tag is selected
7. Set the Exposed HTTP port to `80`
8. Set the Healthcheck port to `80`
9. Set the Healthcheck path to `/health`
10. Toggle **Start Command** on
11. Add the following parameters to **CMD**: `--model-id deepseek-ai/deepseek-llm-7b-chat`
12. Add your Hugging Face User Access Token to the **Environment Variables** as `HF_TOKEN`. Note that in some examples you might see `HUGGING_FACE_HUB_TOKEN` environment variable used. The `HF_TOKEN` is the new name for the environment variable. The old name `HUGGING_FACE_HUB_TOKEN` is still supported, but going forwards we recommend using the new name.
13. **Deploy container**
(You can leave the **Scaling** options to their default values, however if you wish to enable LLM batching, you can set the **Concurrent requests per replica** option to a value greater than 1. This number represents the number of concurrent requests the deployment accepts)
That's it! You have now created a deployment. You can check the logs of the deployment from the logs tab. When the deployment starts it'll download the model weights from Hugging Face and start the [TGI](https://huggingface.co/docs/text-generation-inference/index) server. This will take few minutes to complete.
{% hint style="warning" %}
For production use, we recommend authenticating/using private registries to avoid potential rate limits imposed by public container registries.
{% endhint %}
## Accessing the deployment
Before you can connect to the endpoint, you will need to generate an authentication token, by going to **Credentials -> Inference API Keys**, and click **Create.**
The **base endpoint URL** for your deployment is in the **Containers API** section in the top left of the screen. This will be in the form of: `https://containers.datacrunch.io//`
### Test Deployment
Once the deployment has been created and is ready to accept requests, you can test that it responds correctly by sending a `List Models` request to the endpoint.
[TGI](https://huggingface.co/docs/text-generation-inference/index) can be deployed as a server that implements the [OpenAI API protocol](https://platform.openai.com/docs/api-reference/introduction). This allows [TGI](https://huggingface.co/docs/text-generation-inference/index) to be used as a replacement for applications using OpenAI API. More information about [TGI](https://huggingface.co/docs/text-generation-inference/index) in general and available endpoints can be found in the [official documentation of TGI](https://huggingface.co/docs/text-generation-inference/index)
Below is an example cURL command for running your test deployment:
{% hint style="info" %}
Notice the added subpath `/v1/models` to the base endpoint URL
{% endhint %}
```bash
#!/bin/bash
curl -X GET /v1/models \
--header 'Authorization: Bearer ' \
--header 'Content-Type: application/json'
```
This should return a response that shows `deepseek-ai/deepseek-llm-7b-chat` model is available for use.
```json
{
"object": "list",
"data": [
{
"id": "deepseek-ai/deepseek-llm-7b-chat",
"object": "model",
"created": 0,
"owned_by": "deepseek-ai/deepseek-llm-7b-chat"
}
]
}
```
## Sending inference requests
As the `List Models` request show us `deepseek-ai/deepseek-llm-7b-chat`, we are ready to send an inference requests to the model.
### Generate API
Generate API `/generate` offers a quick way to get completions for a given prompt.
#### Synchronous request
Below is a Python script that calls the completions endpoint `/generate` with a prompt and returns the completion. Save it to a file named `test_request.py` and run it with `python test_request.py`. Remember to replace `` and `` with the values from your deployment.
```python
import requests
import sys
import signal
def graceful_shutdown(signum, frame) -> None:
print(f"\nSignal {signum} received at line {frame.f_lineno} in {frame.f_code.co_filename}")
sys.exit(0)
def do_test_request() -> None:
url = '/generate'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ',
}
data = {
"inputs": "Solar wind is a curious phenomenon. By studying it's origins",
"parameters": {
"max_new_tokens": 128,
"temperature": 0.7,
"top_p": 0.9
}
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
try:
print(response.json())
except ValueError:
print("Response content is not valid JSON.", file=sys.stderr)
print("Response body:", file=sys.stderr)
print(response.text, file=sys.stderr)
else:
print(f"Request failed with status code {response.status_code}", file=sys.stderr)
print("Response body:", file=sys.stderr)
print(response.text, file=sys.stderr)
if __name__ == "__main__":
signal.signal(signal.SIGINT, graceful_shutdown)
signal.signal(signal.SIGTERM, graceful_shutdown)
do_test_request()
```
**Response**
This returns a synchronous response with the completion of the prompt:
```json
{
"generated_text": " and its impact on the Earth we can learn a lot about the Sun and our own planet. The Solar wind is a stream of charged particles that are constantly emitted from the Sun. This stream moves at high speeds and can be measured in the solar system as far as the Voyager spacecrafts, which are now leaving the solar system.\n\nThe solar wind is made up of electrons, protons, and heavier ions. These particles are moving at speeds of hundreds of kilometers per second. As they move away from the Sun, they carry with them the Sun's magnetic field. This field is important"
}
```
#### Streaming request
Same example as above, but streaming out the response using Generate API stream endpoint `/generate_stream`. Save it to a file named `test_request.py` and run it with `python test_request.py`.
```python
import requests
import sys
import signal
def graceful_shutdown(signum, frame) -> None:
print(f"\nSignal {signum} received at line {frame.f_lineno} in {frame.f_code.co_filename}")
sys.exit(0)
def do_test_request() -> None:
url = '/generate_stream'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ',
'Accept': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
}
data = {
"inputs": "Solar wind is a curious phenomenon. By studying it's origins",
"parameters": {
"max_new_tokens": 128,
"temperature": 0.7,
"top_p": 0.9
}
}
try:
with requests.post(url, headers=headers, json=data, stream=True) as response:
if response.status_code == 200:
print("Stream started. Receiving events...\n")
for line in response.iter_lines(decode_unicode=True):
if line:
print(line)
else:
print(f"Request failed with status code {response.status_code}", file=sys.stderr)
print("Response body:", file=sys.stderr)
print(response.text, file=sys.stderr)
except requests.RequestException as e:
print(f"An error occurred: {e}", file=sys.stderr)
if __name__ == "__main__":
signal.signal(signal.SIGINT, graceful_shutdown)
signal.signal(signal.SIGTERM, graceful_shutdown)
do_test_request()
```
**Response**
This returns a streaming response with the completion of the prompt:
```
Stream started. Receiving events...
event:response
data:{"index":1,"token":{"id":29493,"text":",","logprob":-0.61816406,"special":false},"generated_text":null,"details":null}
event:response
data:{"index":2,"token":{"id":1246,"text":" we","logprob":-0.16967773,"special":false},"generated_text":null,"details":null}
event:response
data:{"index":3,"token":{"id":1309,"text":" can","logprob":-0.1661377,"special":false},"generated_text":null,"details":null}
...
```
### Chat Completions API
The chat completions API `/v1/chat/completions` is a more dynamic, interactive way to communicate with the model, allowing back-and-forth exchanges that can be stored in the chat history. Notice that the prompt format is different from the completions API.
#### Synchronous request
Below is a Python script that calls the chat completions endpoint `/v1/chat/completions` with a prompt and returns the completion. Save it to a file named `test_request.py` and run it with `python test_request.py`. . Remember to replace `` and `` with the values from your deployment.
```python
import requests
import sys
import signal
def graceful_shutdown(signum, frame) -> None:
print(f"\nSignal {signum} received at line {frame.f_lineno} in {frame.f_code.co_filename}")
sys.exit(0)
def do_test_request() -> None:
url = '/v1/chat/completions'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ',
}
data = {
"model": "deepseek-ai/deepseek-llm-7b-chat",
"messages":[
{"role": "user", "content": "What is deep learning?"}
],
"stream":False
}
try:
with requests.post(url, headers=headers, json=data, stream=False) as response:
print(response.json())
except requests.RequestException as e:
print(f"An error occurred: {e}", file=sys.stderr)
if __name__ == "__main__":
signal.signal(signal.SIGINT, graceful_shutdown)
signal.signal(signal.SIGTERM, graceful_shutdown)
do_test_request()
```
**Response**
This returns a synchronous response with the completion of the prompt.
```json
{
"object": "chat.completion",
"id": "",
"created": 1737406192,
"model": "deepseek-ai/deepseek-llm-7b-chat",
"system_fingerprint": "3.0.2-sha-b70f29d",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Deep learning is a subset of machine learning which is based on artificial neural networks. It\\'s a type of algorithm inspired by the structure and function of the brain. These neural networks are designed to simulate the learning process that occurs in a human brain, using layers of interconnected \\'neurons\\' to process and learn from large amounts of data.\n\nDeep learning algorithms can be used in a variety of contexts, such as image and speech recognition, natural language processing, and even in industries like healthcare, finance, and autonomous vehicles. The term \"deep\" refers to the deep neural networks with many layers, allowing them to learn increasingly complex patterns and abstractions from the data."
},
"logprobs": "None",
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 8,
"completion_tokens": 141,
"total_tokens": 149
}
}
```
#### Streaming request
Same example as above, but streaming out the response. Save it to a file named `test_request.py` and run it with `python test_request.py`.
```python
import requests
import sys
import signal
def graceful_shutdown(signum, frame) -> None:
print(f"\nSignal {signum} received at line {frame.f_lineno} in {frame.f_code.co_filename}")
sys.exit(0)
def do_test_request() -> None:
url = '/v1/chat/completions'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ',
'Accept': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
}
data = {
"model": "deepseek-ai/deepseek-llm-7b-chat",
"messages":[
{"role": "user", "content": "What is deep learning?"}
],
"stream":True,
"stream_options": {
"include_usage": True
},
"temperature": 0.8,
"top_p": 0.95
}
try:
with requests.post(url, headers=headers, json=data, stream=True) as response:
if response.status_code == 200:
print("Stream started. Receiving events...\n")
for line in response.iter_lines(decode_unicode=True):
if line:
print(line)
else:
print(f"Request failed with status code {response.status_code}", file=sys.stderr)
print("Response body:", file=sys.stderr)
print(response.text, file=sys.stderr)
except requests.RequestException as e:
print(f"An error occurred: {e}", file=sys.stderr)
if __name__ == "__main__":
signal.signal(signal.SIGINT, graceful_shutdown)
signal.signal(signal.SIGTERM, graceful_shutdown)
do_test_request()
```
**Response**
This returns a streaming response with the completion of the prompt.
```
Stream started. Receiving events...
event:response
data:{"id":"fb7bb0fbd2ee4316b041f03a71264597","object":"chat.completion.chunk","created":1737390987,"model":"deepseek-ai/deepseek-llm-7b-chat","choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":"","matched_stop":null}],"usage":null}
event:response
data:{"id":"fb7bb0fbd2ee4316b041f03a71264597","object":"chat.completion.chunk","created":1737390987,"model":"deepseek-ai/deepseek-llm-7b-chat","choices":[{"index":0,"delta":{"role":null,"content":" Deep"},"logprobs":null,"finish_reason":"","matched_stop":null}],"usage":null}
event:response
data:{"id":"fb7bb0fbd2ee4316b041f03a71264597","object":"chat.completion.chunk","created":1737390987,"model":"deepseek-ai/deepseek-llm-7b-chat","choices":[{"index":0,"delta":{"role":null,"content":" learning"},"logprobs":null,"finish_reason":"","matched_stop":null}],"usage":null}
...
```
## Conclusion
This concludes our tutorial how to call the [TGI](https://huggingface.co/docs/text-generation-inference/index) endpoint with `deepseek-ai/deepseek-llm-7b-chat` model. You can now use the [TGI](https://huggingface.co/docs/text-generation-inference/index) endpoint to generate completions for your prompts.
Also check out also other [TGI](https://huggingface.co/docs/text-generation-inference/index) standard endpoints such as `/health`, `/info` or `/metrics` to monitor the health of the deployment.